
By Seiyoung Bae and Kimberly Mann Bruch
Terms & Definitions
SQL
SQL, which stands for Structured Query Language, is a specialized programming language used to manage and
retrieve data from databases.It lets you ask questions (queries), add new information, change existing data, or
organize data in tables inside a database.
Schema
A schema is a blueprint or a plan that shows how data is organized within a database. It describes what tables
exist, what columns are in those tables, what types of data go in which column, and how different tables are
related to each other. Schemas help make sure information
is stored in a consistent and organized way.
LLM
LLM stands for Large Language Model. These are very advanced artificial intelligence systems trained on
huge amounts of text. They can understand and generate human-like text, answer questions, summarize
information, and even translate languages. Popular examples include ChatGPT and other AI chatbots.
SchemaPile
SchemaPile is a massive collection of database schemas gathered from public code repositories. It includes
details about over 220,000 database structures, including tables, columns, rules, and relationships, and is
used by researchers and developers to study how databases
are designed and to train machine learning models.
Researchers from the University of California San Diego have developed a framework that could significantly improve the accuracy of popular AI models.
The project, called SNAILS for “Schema Naming Assessments for Improved LLM-Based SQL Inference,” introduces a novel approach to enhancing natural language interfaces to databases by focusing on something overlooked – the names of tables and columns in the database.
The research team was led by Kyle Luoma, a doctoral student at UC San Diego and research scientist at the United States Military Academy West Point. Luoma worked closely with Jacobs School of Engineering Computer Science and Engineering Associate Professor Arun Kumar, who is also affiliated with the Halicioglu Data Science Institute at UC San Diego’s new School of Computing, Information and Data Sciences, which aims to advance data science and AI education.
Luoma and Kumar discovered that the way database schema identifiers are named significantly impacts the performance of large language models (LLMs) – the type of model utilized by popular AI tools, such as ChatGPT and Google Gemini – when translating natural language into SQL. SNAILS improves how artificial intelligence systems interpret natural language queries and convert them into accurate SQL database commands.
“LLMs do better when database designers name their tables and columns using human-friendly language and with SNAILS, we offer the first formal way to measure and fix this in existing or future databases,” Luoma explained.
Using the SNAILS benchmark, the team evaluated several of the most popular AI models – ChatGPT, Gemini, CodeLlama and a fine-tuned CodeS model. They found that models consistently performed better on databases with more natural names. Particularly for smaller or open-source models, execution accuracy improved as much as 20% when cryptic names were replaced with natural ones. Even the top-performing models like GPT-4o and Gemini showed measurable increase.
“For databases already in production, renaming things can be hard,” Luoma said. “So we recommend creating virtual natural views of schemas using SQL views, which lets organizations keep their original database intact while presenting a more LLM-friendly version to the AI.”
SNAILS reveals naming patterns that cause confusion – such as spaces in identifiers or names that include the word “table” – and offers automated tools to fix them. The team’s classifiers can help engineers assess their schema’s naturalness and make informed decisions before integrating AI-based interfaces.
To evaluate the reality of the problem, the team analyzed more than one million column names from the SchemaPile dataset and found that more than 30% of real-world schemas contain several least natural identifiers. These results emphasize the relevance of SNAILS for practitioners and researchers alike.
“LLMs have revolutionized coding, but in the database querying context there is still a ways to go to bridge the gap with the messiness of real-world databases – this work shows that it is an impactful and feasible avenue to adapt and evolve how practitioners create and manage database schemas to be more LLM-amenable and in turn, more user friendly,” Kumar said. “At SIGMOD, this research received interest from both database practitioners and researchers interested in extending Kyle’s ideas and benchmark to other (human) languages.”
The research was presented at the 2025 ACM SIGMOD/PODS International Conference on Management of Data.
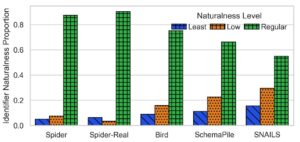
Caption: The frequency of identifiers of different naturalness levels across benchmarks and schema collections are shown in this chart, which provoked the SNAILS team to identify a need for a new set of real-world databases that contained a variety of different naming patterns. Read more about this on the SNAILS page.


